L'IA industrielle sans la complexité MLOps. Entraînez sur vos données, déployez en un clic à l'edge ou dans le cloud. Pas de Kubernetes. Pas de doctorat requis.
ONNX est le standard ouvert pour l'échange de modèles ML. Entraînez en PyTorch, TensorFlow ou scikit-learn — exportez une fois — exécutez partout : CPU, GPU, NPU edge ou cloud.
Indépendant du framework. Passez de PyTorch à ONNX Runtime sans réécrire le code d'inférence.
ONNX Runtime applique des optimisations de graphe spécifiques au matériel. Inférence plus rapide, latence réduite à l'edge.
Fonctionne sur ARM CPU, Intel NPU, GPU Nvidia — même un Raspberry Pi. Aucune dépendance cloud pour l'inférence.
Licencié Apache 2.0. Supporté par Microsoft, Meta, Google, AWS. Zéro lock-in éditeur.
Une bibliothèque de patterns de prédiction prêts à l'emploi, à brancher directement sur votre pipeline de données.
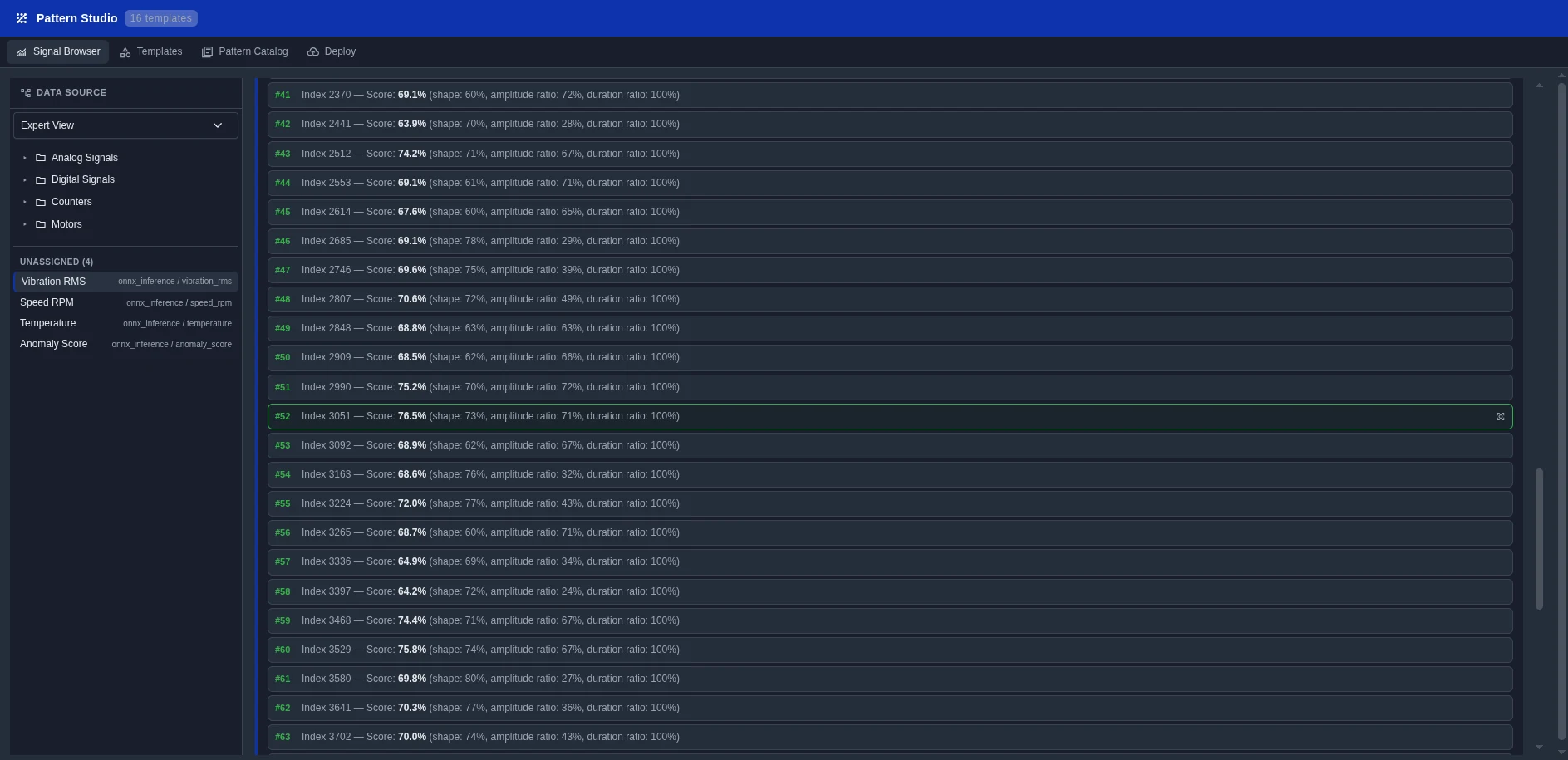
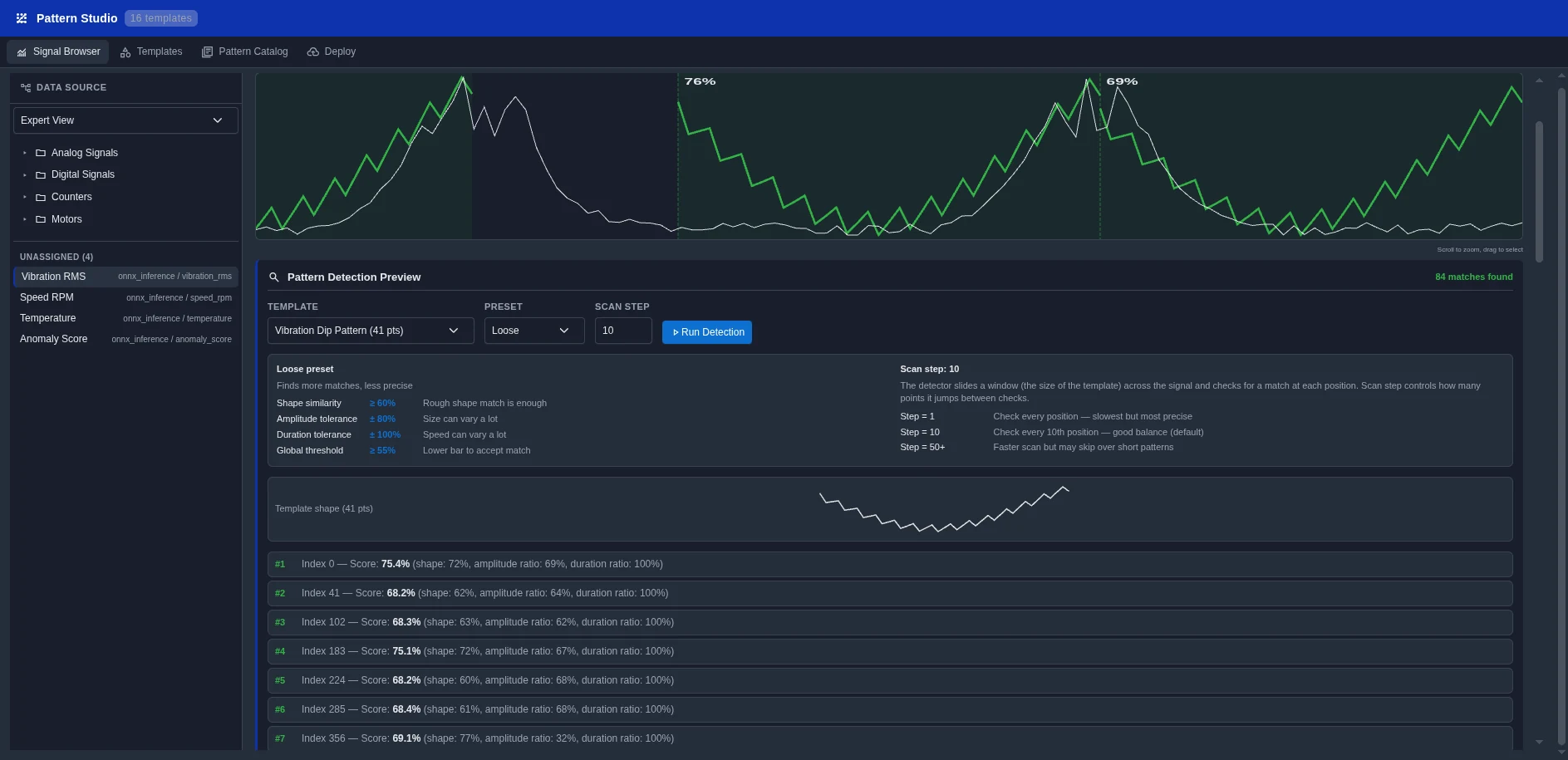
Déploiement de modèles par glisser-déposer. Choisissez un pattern, fournissez les données d'entraînement, cliquez Déployer. Aucune connaissance Kubernetes ou MLOps requise.
Chaque pattern est un pipeline ML éprouvé, préconfiguré pour les données industrielles. Choisissez, fournissez vos données, déployez.
Forecastream — prévision probabiliste sur n'importe quel tag avec une bande de confiance p10–p90. Zero-shot, sans entraînement ni tuning. Détectez les excursions minutes, heures ou jours à l'avance.
L'auto-encodeur non supervisé apprend le comportement normal et déclenche des alertes lorsque les signaux dévient. Opérationnel dès le premier jour.
Modèle de régression entraîné sur l'historique de pannes de votre équipement — prédit le temps avant panne en heures, jours ou cycles.
Estimez les variables non mesurées (chimie, qualité, efficacité) à partir de capteurs corrélés. Remplacez les analyses laboratoire coûteuses.
Notez chaque run de production par rapport à une trajectoire de référence 'dorée'. Détectez les déviations avant qu'elles deviennent des défauts.
L'optimiseur multi-variables suggère des changements de consignes pour minimiser l'énergie, maximiser le rendement ou atteindre la qualité cible.
Modèles de vision basés ONNX pour l'inspection qualité, la surveillance sécurité et la visualisation de procédé — caméras tuyères incluses.
Industream s'intègre avec le Model Context Protocol (MCP) pour que n'importe quel LLM puisse interroger les données d'usine en temps réel, exécuter des calculs et déclencher des actions via des outils typés.
"Quelle est la tendance de température sur le four 3 ces 8 dernières heures ?" — Le LLM interroge DataBridge via MCP et répond en langage naturel.
L'agent LLM surveille les scores d'anomalie et rédige un ticket de maintenance avec le contexte de cause racine, prêt pour validation humaine.
Déclenchez des pipelines FlowMaker via des outils MCP. L'agent décide quand et quoi exécuter selon les conditions en temps réel.
Industream expose les données & actions d'usine comme des outils MCP. N'importe quel LLM compatible MCP peut s'y connecter — frontière ou souverain, cloud ou on-prem, derrière votre pare-feu. Vos données ne quittent jamais votre périmètre sauf si vous le décidez.
Pas un module rajouté après coup. AI Engine est la branche de calcul optionnelle entre FlowMaker et DataLake. Désactivez-la si vous n'avez besoin que du stockage brut — activez-la quand vous êtes prêt à prédire.
AI/ML Workers (en surbrillance) est la branche de calcul optionnelle — désactivez si non requis, activez quand vous êtes prêt à prédire.
Connectez vos données dans DataLake. Choisissez un pattern dans Pattern Studio. Déployez. La boucle complète prend moins de 2 heures.