Industrielle KI ohne MLOps-Aufwand. Auf Ihren Daten trainieren, mit einem Klick an der Edge oder in der Cloud deployen. Kein Kubernetes. Kein Data-Science-Studium erforderlich.
ONNX ist der offene Standard für den ML-Modellaustausch. In PyTorch, TensorFlow oder scikit-learn trainieren — einmal exportieren — überall ausführen: Edge-CPU, GPU, NPU oder Cloud.
Framework-unabhängig. Von PyTorch zu ONNX Runtime wechseln, ohne Inferenzcode neu schreiben zu müssen.
ONNX Runtime wendet hardwarespezifische Graph-Optimierungen an. Schnellere Inferenz, geringere Latenz an der Edge.
Läuft auf ARM-CPUs, Intel-NPUs, Nvidia-GPUs — sogar einem Raspberry Pi. Keine Cloud-Abhängigkeit für Inferenz.
Apache 2.0 lizenziert. Unterstützt von Microsoft, Meta, Google, AWS. Kein Vendor Lock-in.
Eine Bibliothek vorgefertigter Vorhersagemuster, bereit für Ihre Datenpipeline.
Drag-and-Drop-Modelldeployment. Muster auswählen, Trainingsdaten bereitstellen, Deployen klicken. Kein Kubernetes- oder MLOps-Wissen erforderlich.
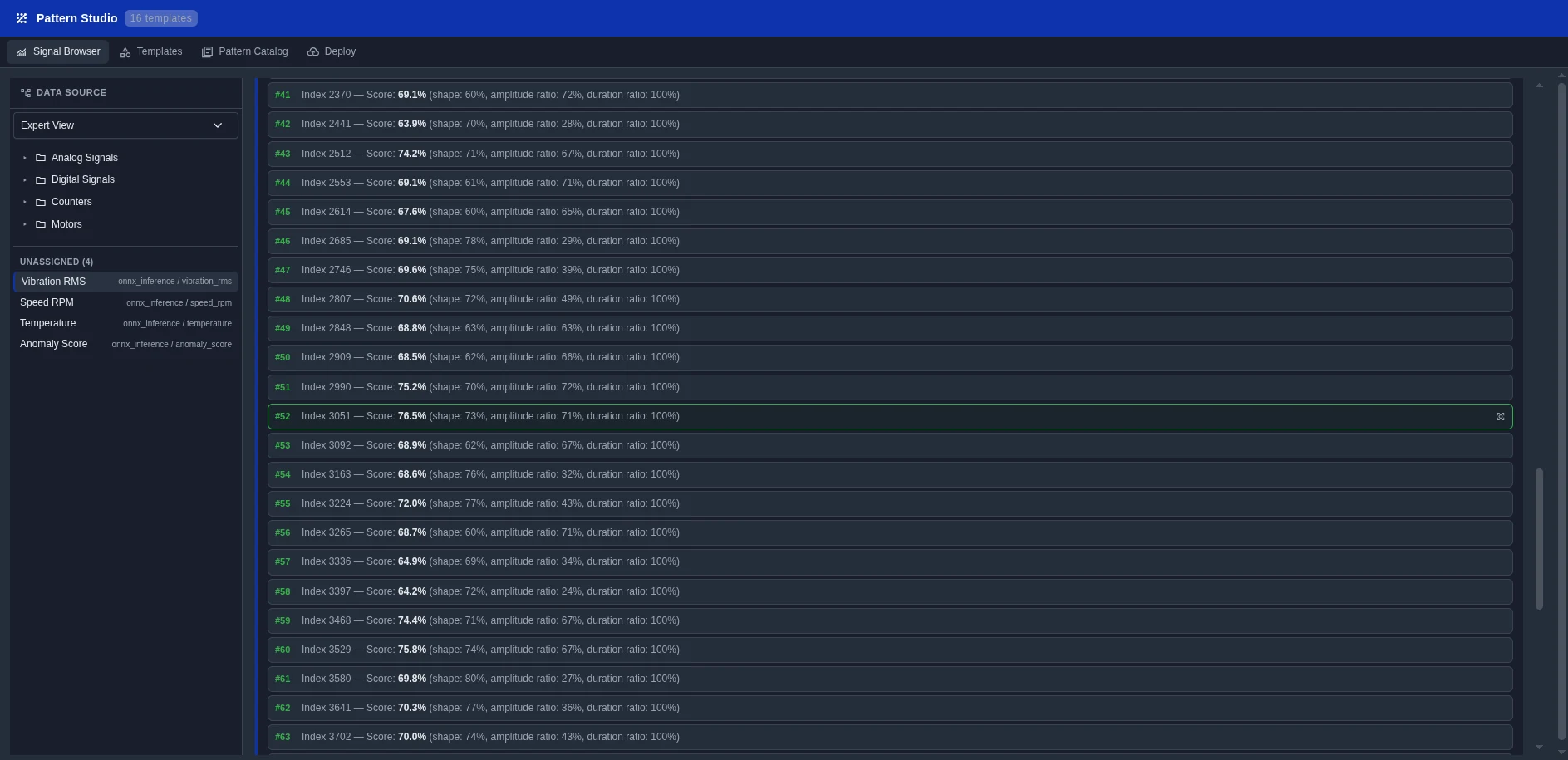
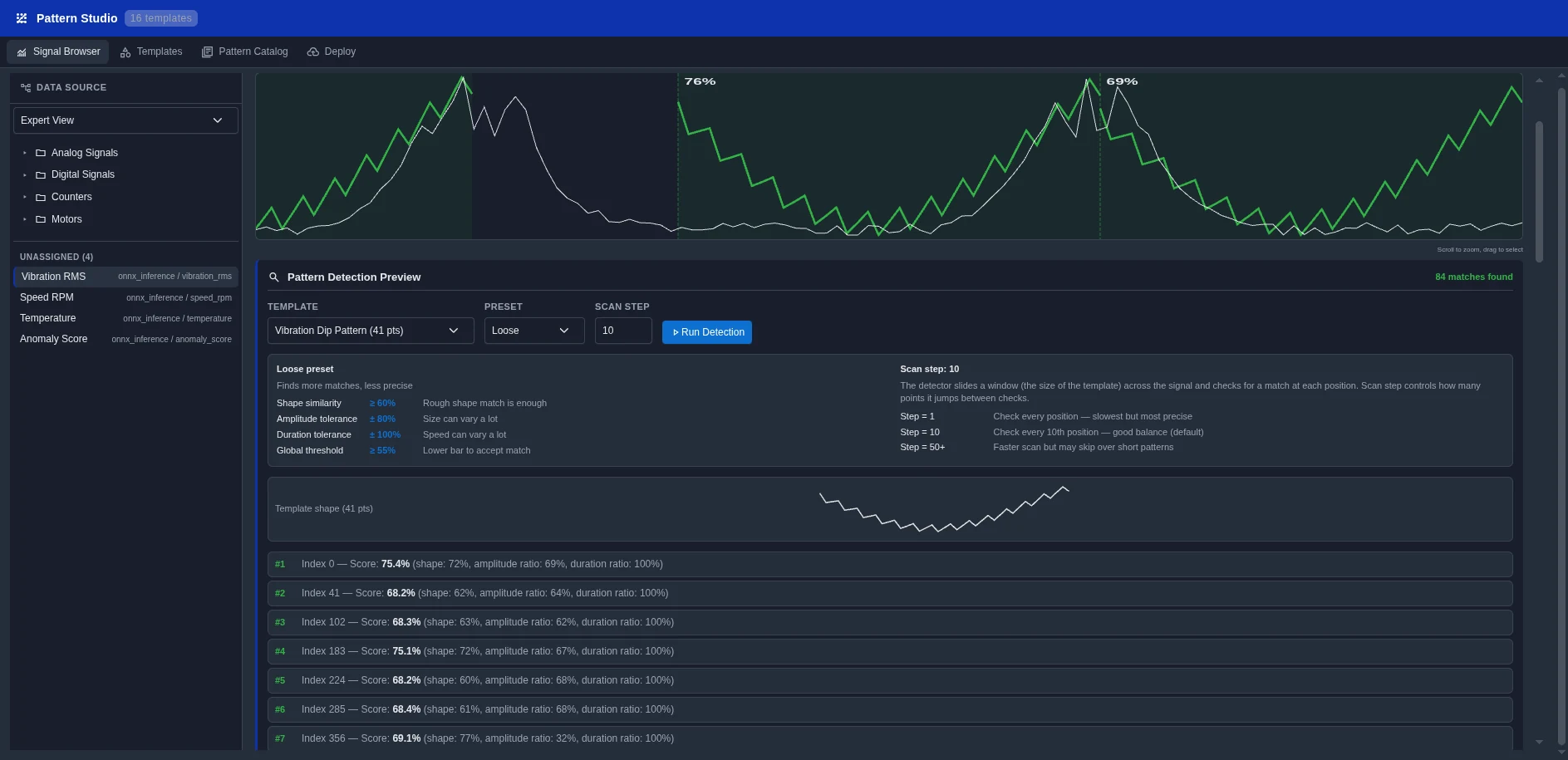
Jedes Muster ist eine bewährte ML-Pipeline, vorkonfiguriert für Industriedaten. Wählen, Daten bereitstellen, deployen.
Google TimesFM, vortrainiert auf 100+ Milliarden Datenpunkten. Zero-Shot-Forecasting auf jedem Tag — kein Training, kein Tuning. Erkennen Sie Ausreißer Minuten, Stunden oder Tage im Voraus.
Unüberwachter Auto-Encoder lernt normales Verhalten und löst Alarme aus, wenn Signale abweichen. Ab dem ersten Tag einsatzbereit.
Regressionsmodell, trainiert auf der Fehlerhistorie Ihrer Anlage — sagt Zeit bis zum Ausfall in Stunden, Tagen oder Zyklen vorher.
Nicht messbare Variablen (Chemie, Qualität, Effizienz) aus korrelierten Sensordaten schätzen. Kostspielige Labormessungen ersetzen.
Jeden Produktionslauf gegen eine goldene Referenztrajektorie bewerten. Abweichungen früh erkennen, bevor sie zu Defekten werden.
Multi-Variablen-Optimierer schlägt Sollwertänderungen vor, um Energie zu minimieren, Ausbeute zu maximieren oder Zielqualität zu erreichen.
ONNX-basierte Vision-Modelle für Qualitätsprüfung, Sicherheitsüberwachung und Prozessvisualisierung — Tuyere-Kameras inklusive.
Industream integriert sich mit dem Model Context Protocol (MCP), damit jeder LLM Live-Anlagendaten abfragen, Berechnungen ausführen und Aktionen über typisierte Tools auslösen kann.
"Wie ist der Temperaturtrend in Ofen 3 in den letzten 8 Stunden?" — Der LLM fragt DataBridge über MCP ab und antwortet in natürlicher Sprache.
LLM-Agent überwacht Anomalie-Scores und erstellt ein Wartungsticket mit Root-Cause-Kontext, bereit zur menschlichen Prüfung.
FlowMaker-Pipelines über MCP-Tools auslösen. Der Agent entscheidet wann und was basierend auf Live-Bedingungen ausgeführt wird.
Industream stellt Anlagendaten und Aktionen als MCP-Tools bereit. Jedes MCP-kompatible LLM kann sich verbinden — Frontier oder souverän, Cloud oder On-Prem, hinter Ihrer Firewall. Ihre Daten verlassen Ihren Perimeter nur, wenn Sie es wollen.
Kein nachträglicher Zusatz. AI Engine ist der optionale Compute-Zweig zwischen FlowMaker und DataLake. Deaktivieren wenn nur Rohspeicherung benötigt — aktivieren wenn Sie bereit sind vorherzusagen.
AI/ML Workers (hervorgehoben) ist der optionale Berechnungszweig — deaktivieren wenn nicht benötigt, aktivieren wenn Sie prognostizieren möchten.
Daten in DataLake verbinden. Muster in Pattern Studio wählen. Deployen. Der gesamte Loop dauert unter 2 Stunden.